
Duplicate material hurts SEO. Just like spamming links and avoiding Google penalties. Duplicate content may harm a site’s organic traffic. Everyone in SEO knows this. That doesn’t mean it’s simple to avoid. Despite your efforts, your site may still have duplicate content problems.
This tutorial will assist you in resolving them. We’ll explain the major causes of duplicating material. Then we’ll go into how to prevent and handle duplicate content problems. First, let’s define duplicate material and why it matters.
Duplicate Content & Google
The simplest approach to explain duplicate content is to look at Google’s definition. In their duplicate content support guidelines, they define it as follows:
‘Substantive blocks of content within or across domains that either completely match other content or are appreciably similar.’
That is straightforward, as is the reason why duplicating content is vital. For the simple reason that what Google intends to offer its consumers with is affected by it. The search engine makes an effort to index and show sites that contain unique information. In order to provide a better user experience, they have made it a priority to do so.
Pages that have duplicate content do not qualify as having separate information, according to this definition. As a result, Google will mark those pages that are duplicated. This implies that just one of the pages with duplicate content will be displayed in the search results. This has the potential to have a significant negative impact on a domain’s organic traffic. Pages that might normally generate more traffic to a website will not be included in the search results at all.
It’s a widespread misunderstanding that Google penalizes websites that have duplicate material on them. That is not the case, however if they detect the usage of duplicate material for harmful purposes, they will take action. A good example of this would be when the material is utilized to influence their search engine rankings. In such scenario, they would do the following:
‘Make appropriate adjustments in the indexing and ranking of the sites involved. As a result, the ranking of the site may suffer, or the site might be removed entirely from the Google index. In which case it will no longer appear in search results.’
It should be clear by now that you want to prevent having duplicate material on your website. Even if you take every precaution, it is possible that it will happen. This may happen in a variety of ways.
How Can Duplicate Content Occur?
As previously said, duplicate material may be displayed on a site on purpose. Usually in an attempt to deceive or manipulate Google’s ranks. Every SEO professional now understands how smart Google’s algorithms are. Only the most naive or callous among them would believe they could get away with such deception.
Duplicate material on a website is much more likely to have evolved organically. This will be due to either technological issues or simple human mistake. It is critical to understand the primary mechanisms through which this may occur. It will assist you in identifying duplicate content problems in your own website. It will also make it simpler to choose the best option.
The following are the reasons of duplicate material that we will discuss:
- Filtering and monitoring URL parameters
- Page overlap across product categories
- Repeating product descriptions
- URL-related technical problems
- Pages that are printer-friendly
- Issues with content production
URL Filtering and Tracking Parameters
URL parameters are suffixes that are appended to the end of a page’s URL. They appear in a variety of contexts and often have little or no effect on the content of a page. The issue is that a URL with a different parameter at the end is a different URL to a search engine. If the material linked to by the ‘two’ URLs is identical, Google will flag it as duplicate content.
Filtering goods on ecommerce sites is a great example of this. Almost all of these sites allow consumers to filter items. They may want to display just items within a certain price range or made of a specific material. The process of filtering the goods results in the addition of a URL parameter to the URL. However, the information shown — the goods, for example – will be replicated elsewhere.
Another instance in point is that of tracking. Tracking parameters allow you to monitor the origins of your website visits. This is important for tracking the ROI of various SEO initiatives. They might look like this: ‘/?source=rss’. They have no effect on a page’s content but appear to a search engine as a unique URL.
Crossover of Product Category Pages
Crossover of category pages is another issue unique to ecommerce sites. Many websites will have several category pages that mainly show the same goods. This is often done for well-intentioned and reasonable reasons.
For example, a present site could include sections like ‘Gifts For Him’ and ‘Father’s Day Gifts.’ Customers may be drawn to the two groups in various ways. The goods shown on the category pages, on the other hand, will be almost similar. That is all that Google will care about, and they may only index one of the pages.
Product Description Duplication
Product pages are one level down from category pages on ecommerce platforms. These are also often a cause of duplicate content problems. Visitors to such sites will expect a brief product description. It will be how the qualities and attributes of the product are marketed to consumers.
Sites that offer a large number of goods often do not generate distinct descriptions for each. Many businesses just copy and paste generic data. That is often supplied by a supplier or manufacturer. As a result, there is a lot of duplication material inside and between websites.
The most serious problems in this instance would arise if your website offers the same goods as a much larger store such as Amazon. Copied descriptions may result in your product page containing duplicate information available on Amazon. Google will almost certainly index Amazon’s website instead of yours.
URL-Related Technical Issues
There are a few additional technical URL problems that may lead to duplicate content concerns, in addition to URL parameters. The first takes the form of’session IDs.’ When site users are granted a’session,’ they are utilized in URLs. This is often done so that goods may be added to a shopping cart and remain there.
As a visitor navigates your site, session IDs are added to each internal link. This results in a large number of URLs, which a search engine may interpret as duplicate material. In a similar vein, messy URLs in a CMS may have the same impact. URLs with category and article parameters that alter order are excellent examples.
Pages that can be printed
It’s possible that your CMS will generate pages that are printer friendly. These pages will be linked to from article pages and elsewhere on your site. Unless you specify otherwise, Google will be able to locate these sites (more on that later).
Only one of the duplicate pages will be filtered and indexed by Google. It’s possible that this is the original or a printer-friendly version. You want your original page to rank, not the one that is optimized for printing. Your advertisements, links, and other material will not be present in the latter.
Problems with Content Creation
The majority of the problems with duplicate material are due to technological reasons. In the sphere of content production, human mistake is a factor. These days, almost every website has a blog or other informative resource. It enables them to offer visitors with valuable information. Duplicate material is often found on blogs.

This may be as a result of entrusting content production to someone you shouldn’t. Someone who is unaware of the issues that duplicate material may bring. They may duplicate or reproduce material without realizing the SEO problems they are causing. Their mistakes may be as simple as using the same title tags all the time. They may be as serious as duplicating material from other websites.
Resolving Duplicate Content Issues
You should now have a better understanding of where your duplicate content problems are coming from. All of the aforementioned reasons are common to numerous sites. Understanding them and determining which have had an impact on your site is critical. This is due to the fact that various causes lend themselves to diverse remedies.
We’ll go through some of the best methods to deal with duplicate content problems. As we proceed, we’ll highlight which of the problems and reasons we’ve previously discussed match best with each solution. Our solutions are divided into two categories:
- Educational and preventive solutions
- Recovery Efforts & Practical Solutions
Educational and preventive solutions
In an ideal world you want to avoid issues with duplicate content before they arise. Knowing about the causes of the issues we’ve discussed is a great starting point. Having that knowledge can help you take steps to ensure that no new content will fall foul of the same problems.
You can, for example, disable session IDs in your system settings. That will prevent the duplicate URL issues those can cause. You could choose to forgo including printer friendly pages on your website at all. It’s not as if many people have cause to print out pages nowadays anyway. A hashtag based tracking campaign can also be a good alternative to parameter based tracking.
Having learnt about the causes of duplicate content, you’re in a position to educate others. They can include web developers or your product team. You can explain to them the issues related to crossover in product categories. That way they’ll know to arrange products accordingly. Freelance or in-house content creators can also be briefed on keeping things unique.
That is in an ideal world. In reality, you may not be able to get ahead of all your duplicate content issues. In those circumstances you need some practical solutions. They will be what can help you to recover from the issues you’re already suffering from.
Practical Solutions & Recovery Efforts
So far, our tutorial should have showed you where your duplicate content problems may have come. We’ve also provided some pointers for preventing future problems. What’s left is to recommend some next steps if your site already has duplicate content problems. There are many choices available to you.
Canonical URLs
Canonical URLs may assist if you have a problem with several URLs pointing to the same content. As previously stated for filtering parameters and category pages. The ‘right’ URL is a canonical URL. It is the URL of the page that you want Google to index from among others that lead to the same content. In each instance, you must determine which page this is.
It’s easy to inform Google which page is your canonical URL after you’ve discovered it. All you have to do is add an HTML element to the other sites’ head> section. It’s known as the ‘canonical link element,’ and it looks like this:’rel=canonical’. When followed by the URL of your selected page, it will direct Google to it.
Redirections to 301
Using’soft redirects’ to point Google to canonical URLs is another term for pointing Google to canonical URLs. This is in contrast to comprehensive 301 redirects. You may also utilize them if you are unable or unwilling to delete duplicate material.
Adding a 301 redirect to a URL directs Google to your desired page. That page will then be indexed by the search engine. This may be a good way to deal with the problem of overlapping product category pages.
All you’d have to do is figure out which of the categories is most important to you in terms of online traffic. The other duplicate or overlapping pages may then be redirected to that category using 301 redirects.
Noindex Tags
A Noindex tag is a directive that may be applied to a page’s HTML source code. It expressly informs Google that you do not want the page indexed. This may prevent Google from indexing a page you want rather than one you don’t.
For problems created by printer-friendly pages, noindex tags are the best answer. Each of the pages should be marked with a Noindex tag. This ensures that the original version of each page is the one Google indexes.
Content Rewriting
Sometimes there is no quick solution for duplicate content problems. If your issue is with blog articles or product descriptions, this is the situation. If they produced duplicate material, you must locate and rewrite the problematic piece. This is a time-consuming and labor-intensive approach. There is just no other method to effectively deal with the issue.
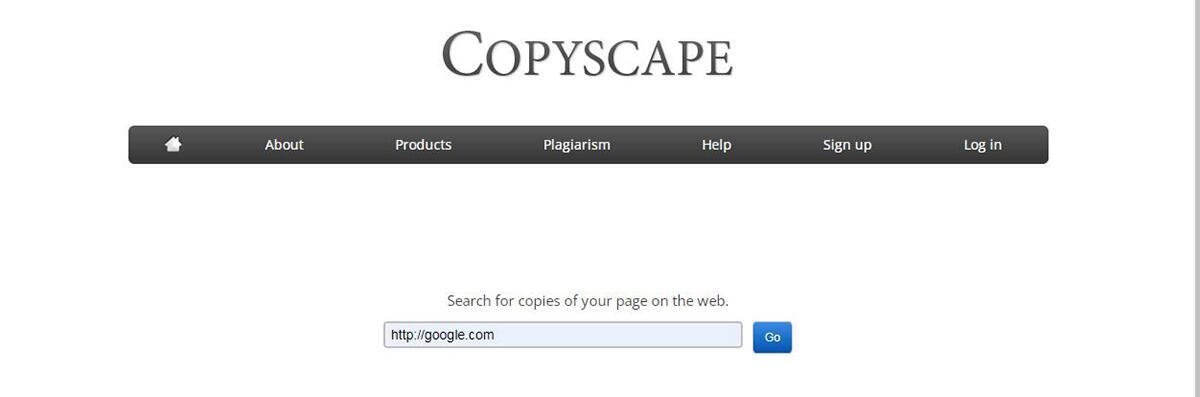
Using a free online service like Copyscape to save time and effort is one method to save time and effort. Copyscape is intended to assist you in creating non-plagiarized material. You may enter a URL and the site will scan the internet for duplicate material. This allows you to identify the specific parts of your material that need to be removed, replaced, or rewritten.


